AI Editors and Peer Reviewers: Error Detection Experiments (Daily Updates)



Unveiling the Future of AI in Science: Scaling Up AI-Powered Error Detection.
It all started with a 10-page paper and a math error that caused a stir in the scientific community. Out of curiosity, Twitter user Ethan Mollick (@emollick) wondered: could an AI spot the mistake with just a prompt like, “Carefully check the math in this paper”? To Ethan's surprise, o1 nailed it in a single shot, even though the data wasn’t part of its training set. The revelation begged a bigger question: should AI checks be a standard in science?
We’re on it 🫡
— ResearchHub Foundation (@ResearchHubF) December 18, 2024
Here’s the plan:
• Proof of concept: Coming by EOY
• Pre-registration for the scaled-up version: Mid-January
Reviewers and developers interested in the scaled-up version, reach out to @jeffyfish9.
Let’s make this happen!https://t.co/SQ3OwA4RvY pic.twitter.com/04yU8f13Dz
Clearly, this idea needs to scale. What if we picked 1,000 published papers at random and asked o1 or o1-Pro to hunt for errors? Imagine the insights—and the improvements—this could bring to the scientific process. It’s a challenge worth exploring, and we are diving in. Even better, it’s gained support: Mark Andreessen suggested he’d help fund the effort, and the ResearchHub Foundation has stepped in to build their own version of the experiment. Here’s the plan:
- Proof of Concept: Coming by the end of the year (EOY).
- Pre-registration of a Scaled Up Version: Mid-January.
Reviewers and developers interested in being part of the full scale version of this groundbreaking project, reach out to Jeffrey Koury (President Researchhub Foundation, jeff@researchhub.foundation). Or sing up via this form.
As the year wraps up, here are the day-to-day updates on how we’re working to make this vision a reality before scaling it up in 2024.
Update-01 | 2024/12/20 |
After two days of sprint, we are now optimizing step 5 and refining the infra construction to scale-up the operation pipeline for step 6. At @ResearchHub https://x.com/ResearchHub we have been doing step 1-4 over the year, and been refining data ever since, an edge for us.
Update-02 | 2024/12/21 |
Today we ran our first few iterations of both Prompt A and Prompt B with a batch of papers from @ResearchHub https://x.com/ResearchHub and from withdrarxiv dataset. To optimize performance, we decided to use RAG on-the-fly pipeline. Gemini 2.0 flash-exp > o1.
Indeed the AI Peer Reviewer driven by Gemini 2, is correct and is not hallucinating. Manually checking this, shows that the author is not paying attention to the bracket. Not an acceptable mistake for defining the critical parameter used in this study.

To show one of the result see below, AI review for the paper https://arxiv.org/abs/2004.12237v2…, which got retracted precisely because theorem 3.9 is invalid.
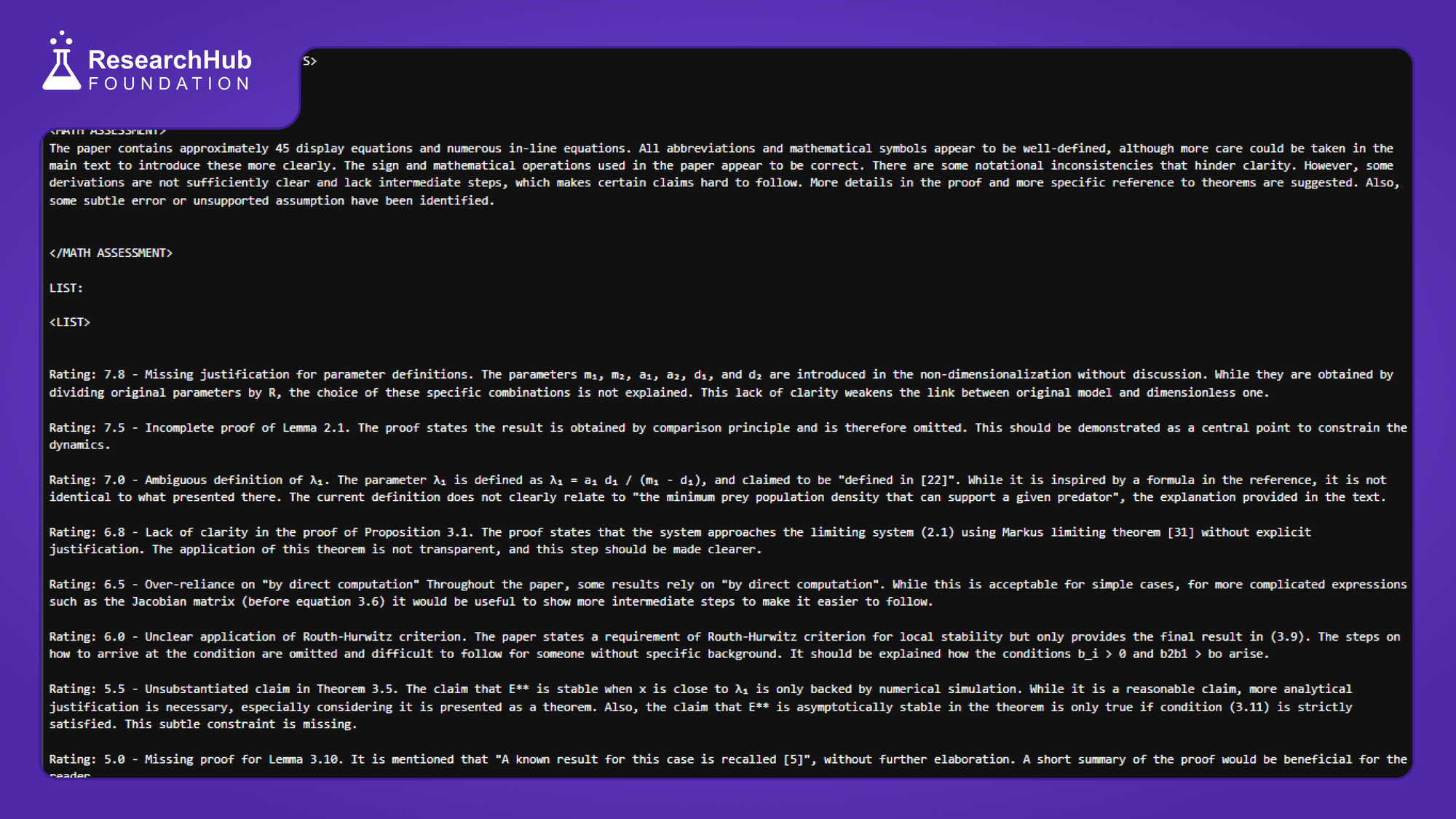
Update-03 | 2024/12/22 |
First batch of prompt engineering experiment results is out. Now improving the structured output for how our AI Peer Reviewers should score errors/issues. Standardized scoring will provide interpretability & help us build robust clusterization algorithm.
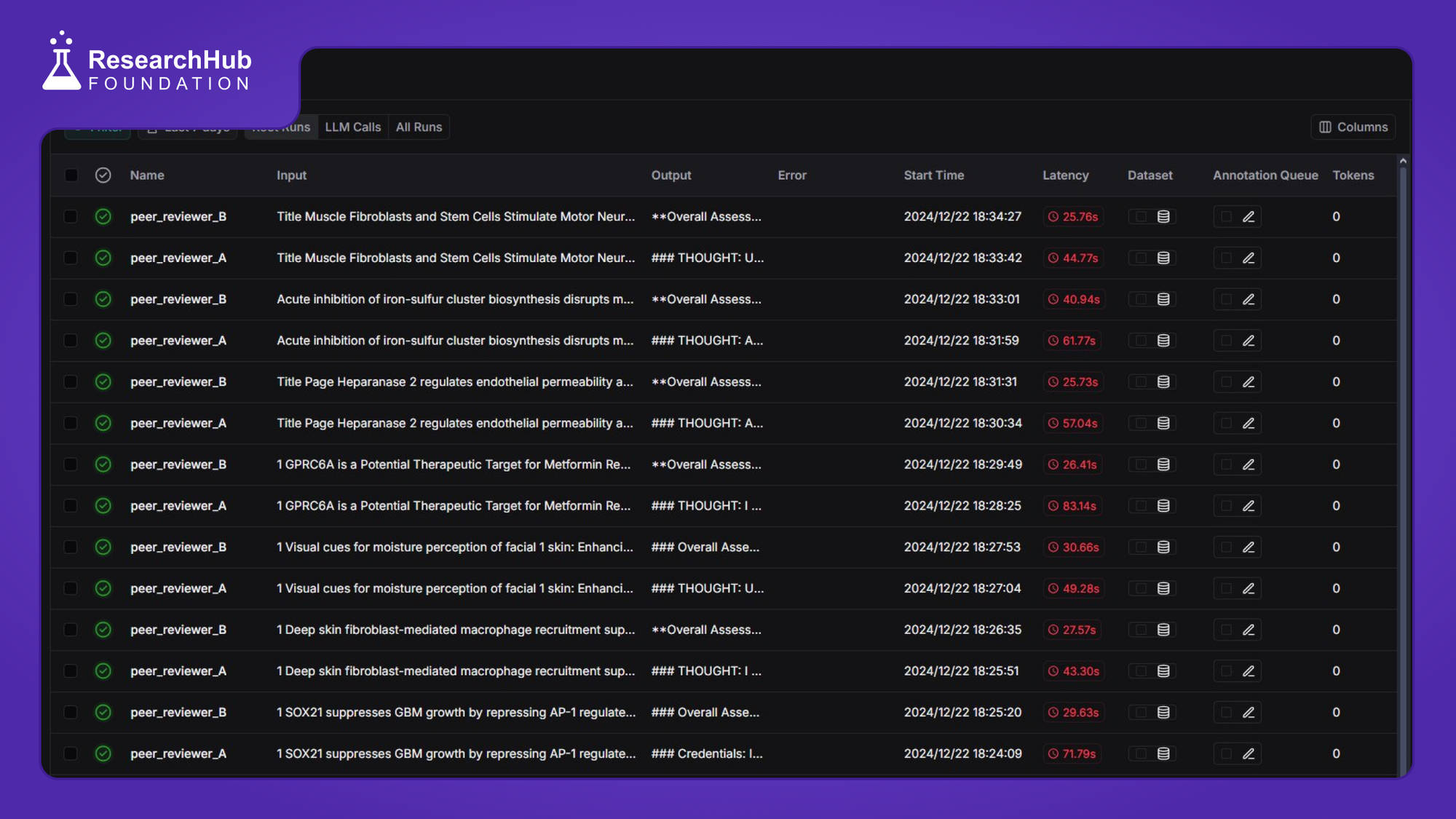
Update - 04 | 2024/12/23 |
After rounds of prompt engineering, we now substantially improve the quality of AI peer reviews by using a multi-agent approach. How? We introduced AI Editor that design 3 complementary Domain Expert AI Peer Reviewer Personas customized for each paper.
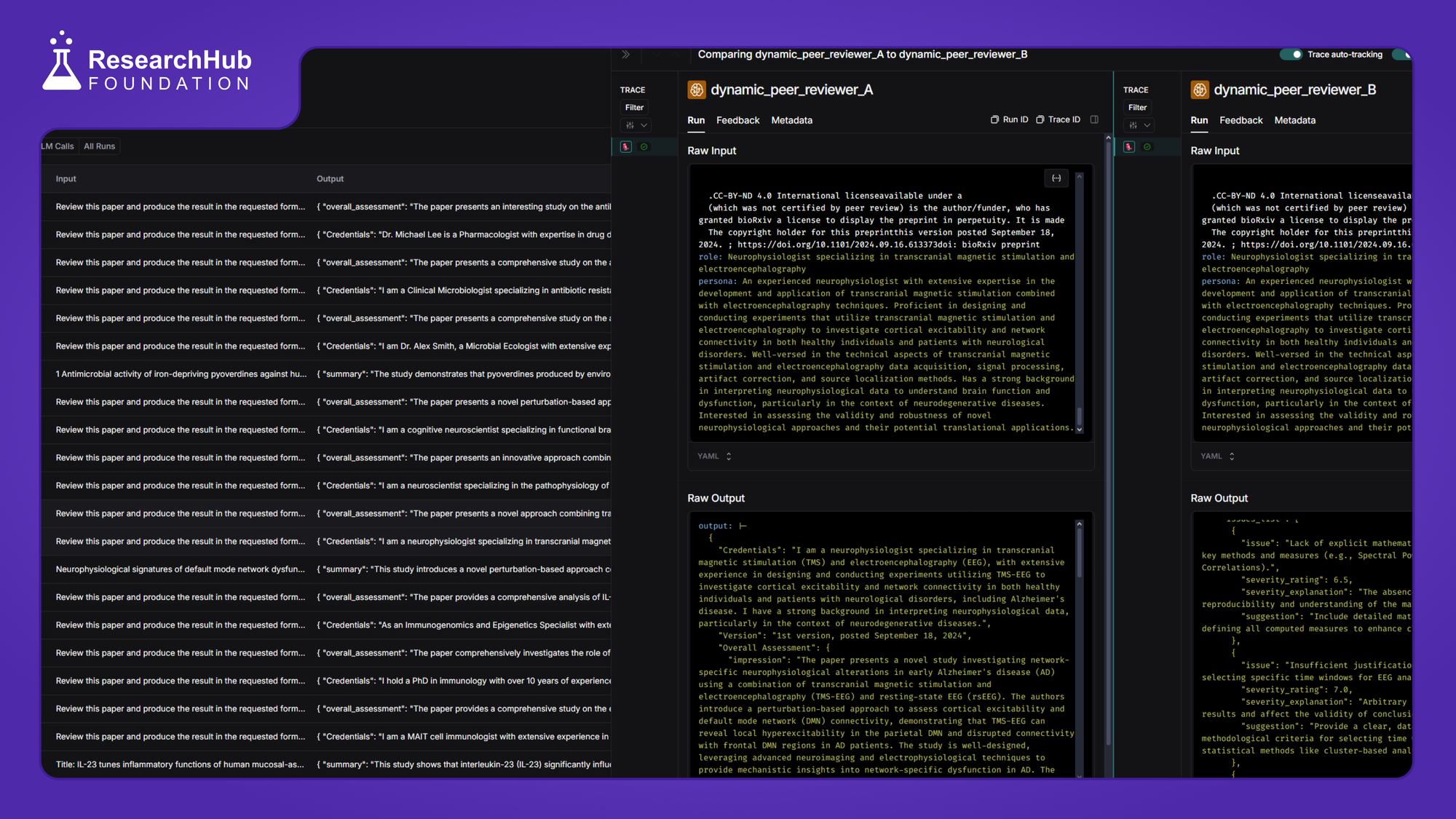
Update - 05 | 2024/12/24 |
Balancing performance and cost. As we introduced more sophistication to ensure high quality reliable error identification and analysis of papers, the cost associated with the process also climbs up. Cost per run have now rise from ~$0.28 closing up to ~$3 for each review set generation. We tested several chunking and documents preprocessing strategy to find balance between performance vs cost.
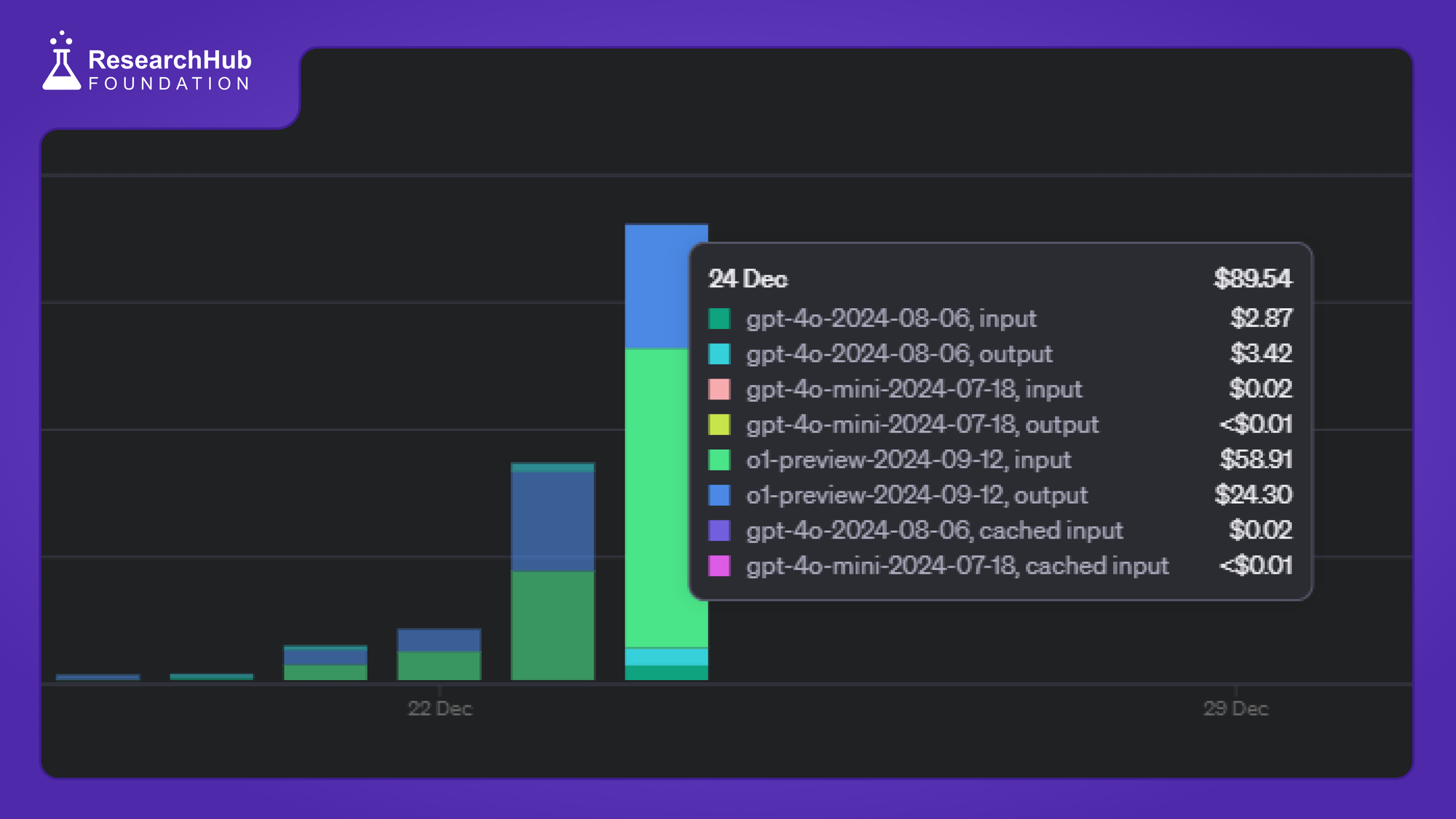
Update - 06 | 2024/12/25 |
Merry Christmas! Today we proceed with establishing the basic layout for the upcoming demo app where user can easily drop a file and get their peer review results returned. Performed a detailed comparison between o1, gemini-2.0 , and claude-3.5. Improved the prompts for result accuracy. We are now getting better with equations.
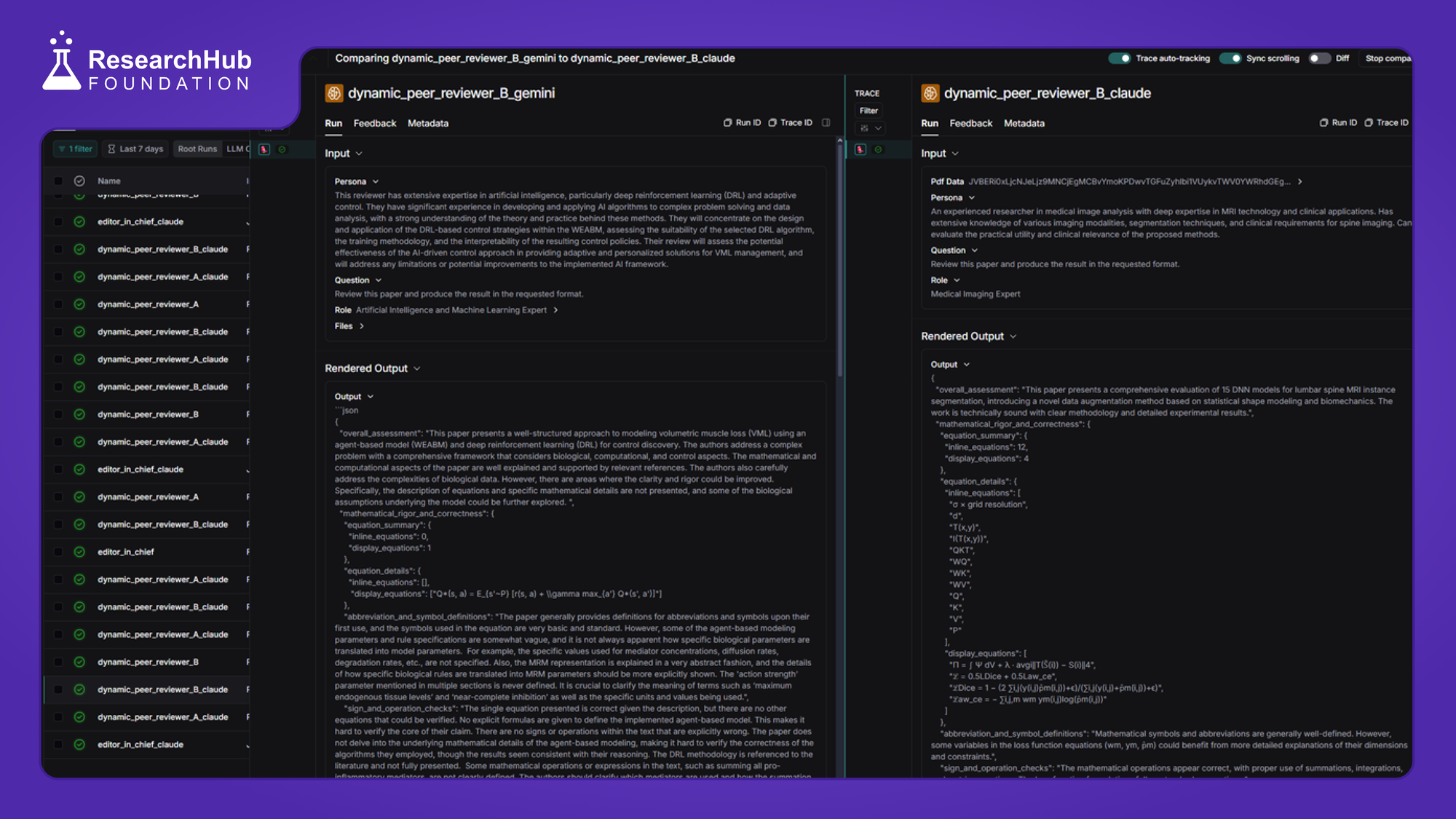
Update - 07 | 2024/12/25 |
Scaling up the comparison between models. We now have 100+ AI reviews under various context. The code is now organized and ready for batch submission when necessary. Working on the UI for demo app. Anthropic submission is now upgraded to highest Tier 4 for allowing higher rate limits. Any suggestion on UI / Features ?
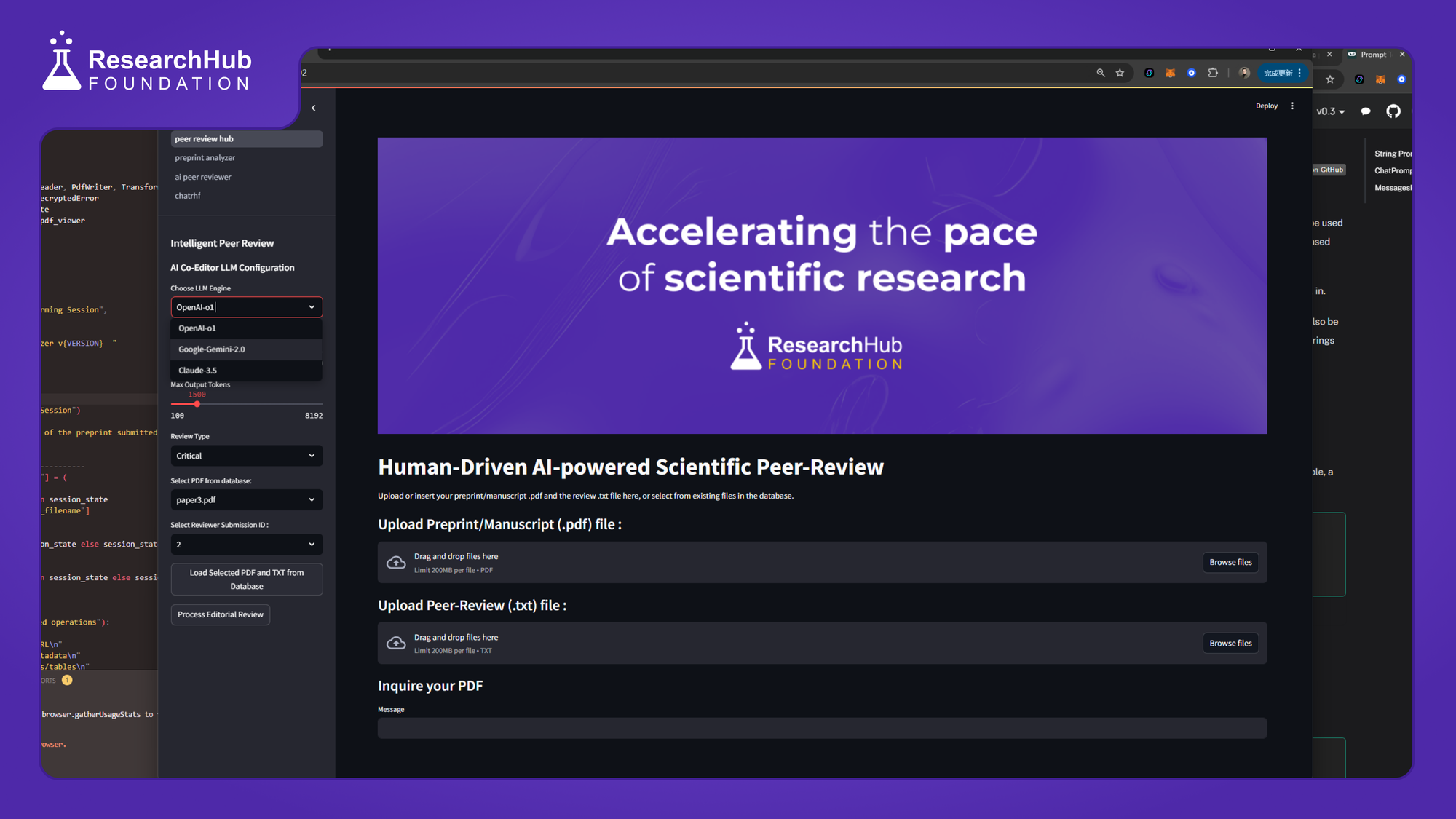
Update - 08 | 2024/12/26 |
To test the capabilities of our AI editors and peer reviewers, we deployed batches of agents to assess mathematically demanding papers known to have errors or issues from the [Withdrarxiv] (https://huggingface.co/datasets/darpa-scify/withdrarxiv) dataset. The data is organized in preparation for developing classification algorithms that will detect whether the AI could accurately categorize papers known to be problematic from those that are known to be error-free or more rigorous ones. We also performed deployment experiments using the newly released DeepSeek-V3 model, which under the same working context, showed comparable performance to Claude, slightly less than OpenAI o1, but certainly inferior to Google's Gemini 2.0.
Update - 09 | 2024/12/27 |
We have finalized the backend Python package for driving the AI agents available on our prototype app. We are now focused on refining the UI/UX to enable users to test and experiment with the AI Editors and Peer Reviewers. Several features are currently being designed and tested for further development. In addition to the current multi-LLM engine AI editorial tools, we will soon include: (1) Custom Prompt Injection, (2) Peer Reviewer Expertise Card, (3) Data Gallery and Explorer, (4) ChatRHF - Scientific Brainstorming with your PDF, and more features to come.
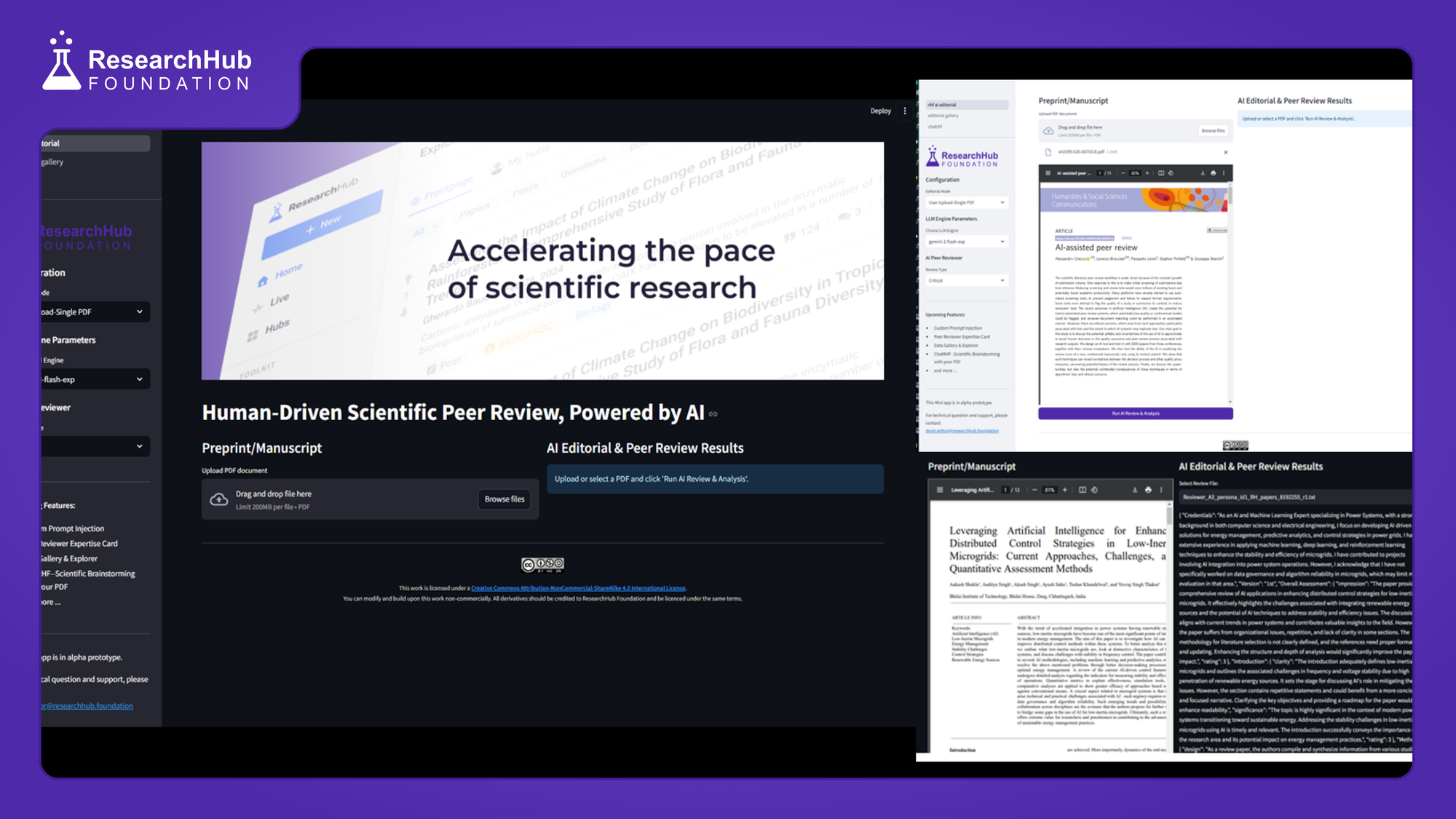
Update - 10 | 2024/12/29 |
First milestone is up. Let's recap what we have achieved in the past 10 days: We have established a working Multi-Agents Infrastructure for AI Editors and Peer Reviewers driven by various SOTA LLM models. We have scanned through batches of scientific preprints and manuscripts, producing 200+ AI-generated editorial comments, reviewer personas, paper analyses, error identification, and ratings. All data is well recorded through our metadata tracing workflow. Keep an eye on the upcoming dataset release. We built a demo app to ensure easy use of paper submission and workflow customization. What's next? We will up our game to produce analytics and utility tools for the community. Stay tuned for more updates. Join our waitlist and be one of the first who can get hands-on with the app and help us do more human evaluations, pushing the boundaries of how Human and AI can accelerate science together.



