Overcoming Goodhart’s Law in Scientific Research





ResearchHub is introducing a novel reputation and reward algorithm designed to help fix academia's broken incentive structure by directly rewarding high-quality research and the scientists who create it.
In this post, we will explain why this approach is sorely needed and how it will benefit scholars around the world.
The Current Publishing Landscape for Researchers
In modern day academia it is essential for any scientist to accrue journal publications if they want to have a successful career. This is because scientific funders rely on a given researcher’s publication history to determine their eligibility for future grant funding. Reasonably, grant givers feel that if a scientist regularly publishes in high prestige academic journals they are probably a high-quality researcher and therefore likely to be a safe investment for future grant funding.
Over the last half century academic publishing has become a big business. In 2023, the global scholarly publishing industry generated over $19b in revenue. Many journals have recognized the tremendous value that lies within their role as arbiters of academic reputation and have decided to monetize it in ways that are detrimental to the greater scientific community as a whole.
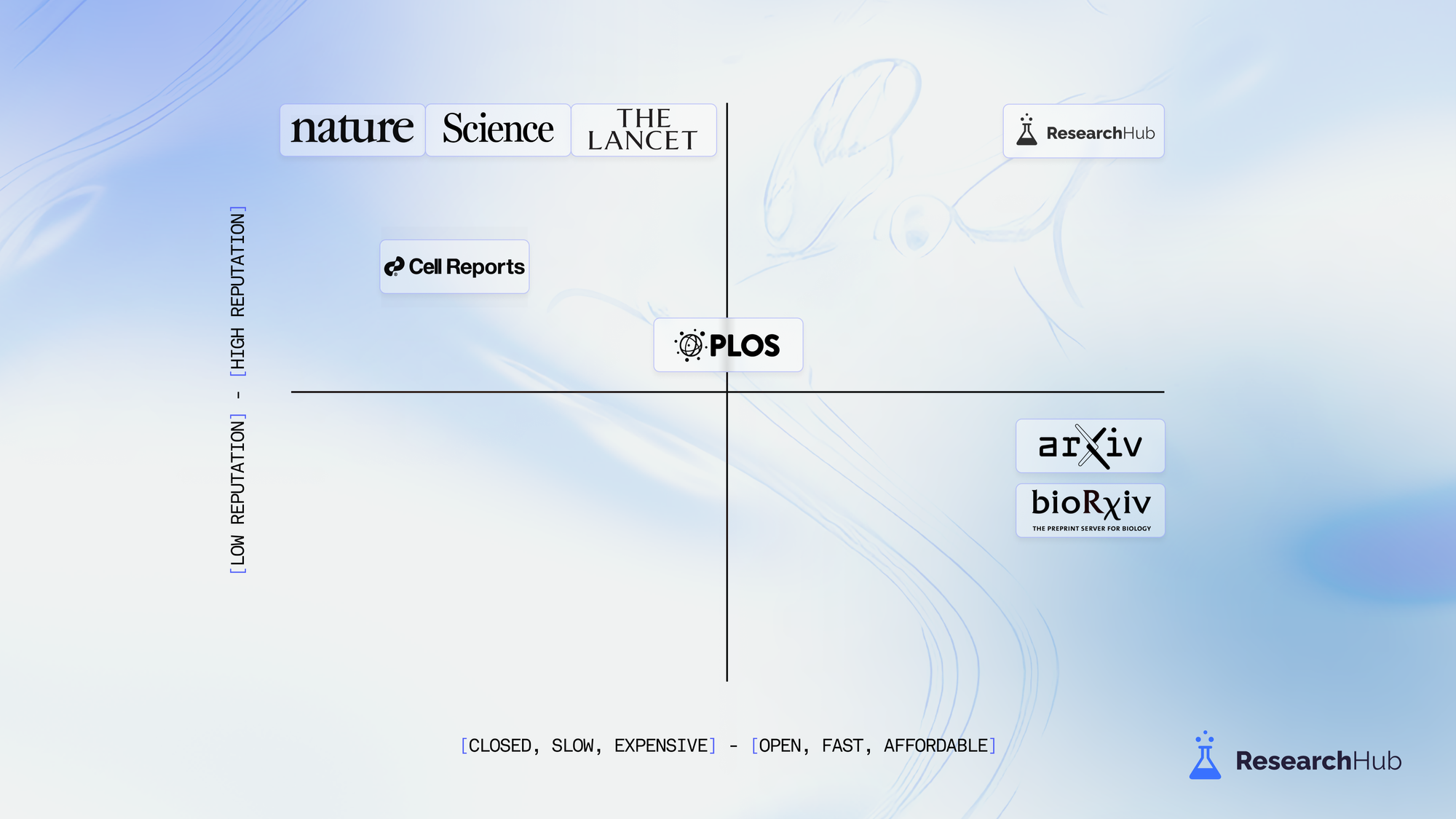
Preprint servers were built out of a desire to return academic publishing to its core value proposition - the timely dissemination of scientific literature. They skip the process of peer review and allow scientists to directly share manuscripts with the world as soon as their work is ready for public consumption.
Unlike traditional academic journals, preprint servers are open access, fast, and have no publication costs. Although their adoption is growing at an exponential rate, they are still dwarfed by traditional peer-reviewed journals because they do not confer the same degree of academic reputation in the eyes of scientific funders.
At ResearchHub, we are building the best of both worlds. Our community is organizing a next-generation scientific marketplace that aims to allocate funding directly to high quality science and the researchers who create it. Our hope is these novel financial incentives will encourage researchers to publish science in a way that maximizes the likelihood of reproducibility in the future.
Goodhart’s Law has Eroded the Value of Bibliometrics
The core problem arises out of the difficulty associated with objectively measuring the quality of any given scientist or the research they publish. To help address this issue bibliometrics, or citation-based metrics such as impact factor and h-index, have gained popularity as tools to help scientific patrons assess research quality. While they were initially useful, over time decisions about access to scientific funding and career progression have become overly dependent on these bibliometrics.
"When a measure becomes a target, it ceases to be a good measure" - Goodhart's law
As Goodhart’s law predicts, these metrics are now being gamed and they no longer represent a meaningful indicator of scientific quality. In fact, oftentimes the opposite is true. Financial pressures mediated by the overuse of bibliometrics push researchers to engage in questionable research practices (QRPs) such as publication biases, p-hacking, and in extreme cases intentional scientific misconduct.
Sadly, over the past few years stories of scientific fraud have become so common they are now regularly covered by the largest mainstream media outlets.
- 235 papers published from 2004 to 2023 mention experiments conducted within cell lines that do not exist.
- Half of cancer biology papers fail independent replication efforts.
- The initial underlying research describing the amyloid-beta hypothesis for the pathology of Alzheimer’s disease contain intentional image manipulations.
It is no wonder the public is losing trust in our world’s scientific institutions. At ResearchHub, we believe this is truly a shame. The only path forward for the scientific community to regain the world’s trust is to accept the immutable nature of Goodhart’s law and align financial rewards with healthy research behaviors.
Overcoming Goodhart’s law: Targets > Metrics
Despite our best efforts and intentions, any metric we use in an attempt to measure research quality will inevitably be gamed and eventually rendered obsolete. The solution to this problem relies on confronting this reality and embracing Goodhart's law from the outset.
While it may be impossible to objectively measure scientific quality, creating targets for behavior is rather simple. This is our goal for ResearchHub’s v2 reputation and reward algorithms; to create a system of both financial and reputational incentives that serve as targets for behavior that encourage scientists to partake in healthy research behaviors.
Now, let’s take a look at the technical details of how these algorithms are implemented.
Reputational Incentives:
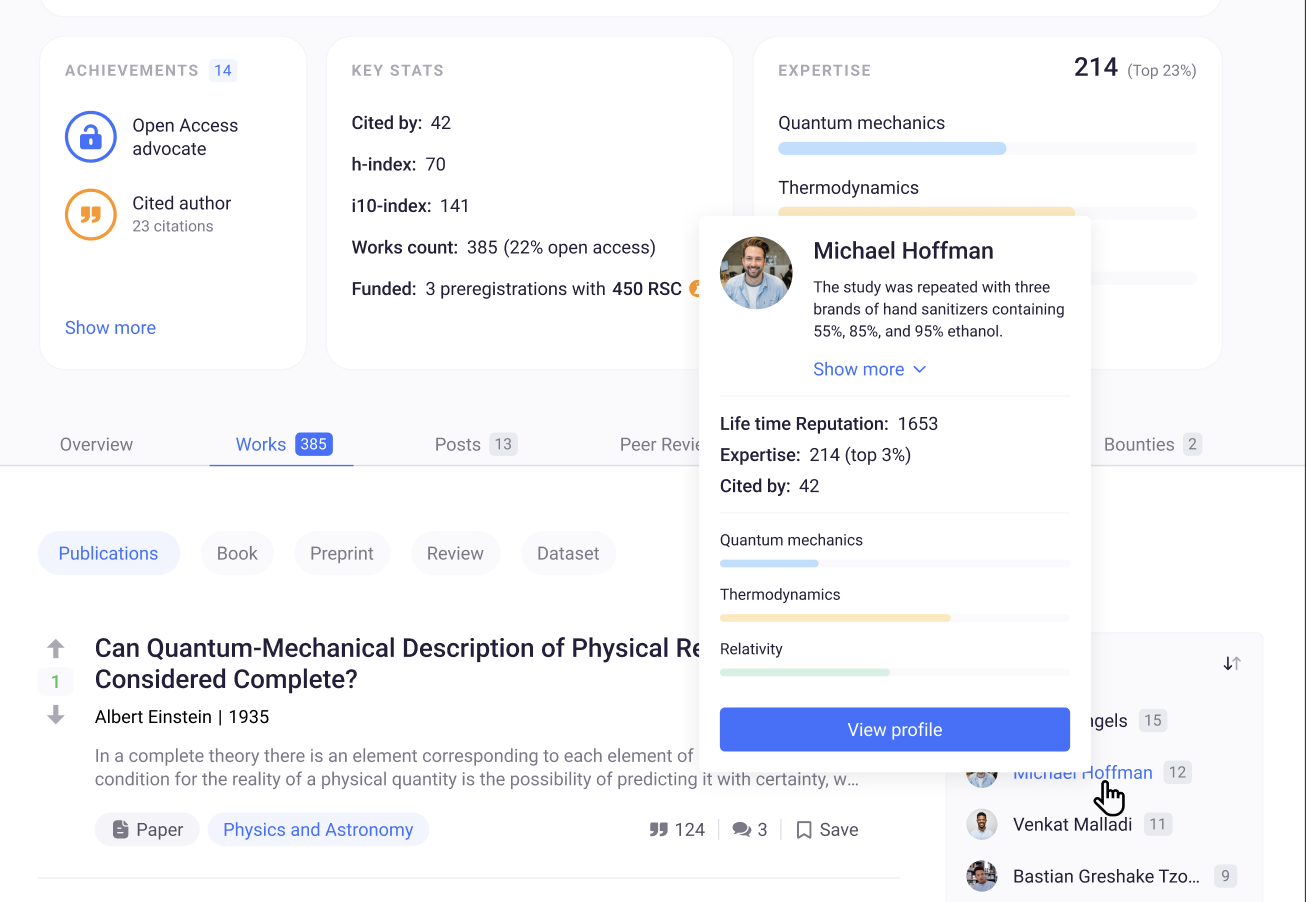
Proper documentation and assessment of reputation is an integral aspect of science. At ResearchHub we want to give users more context on who they interact with, who is making claims, and what their expertise is. REP v2 is surfaced most notably in the newly revamped Author Profile Pages which highlight the “Reputation” of a given author in their fields of expertise along with key statistics from their works, research achievements, and more.
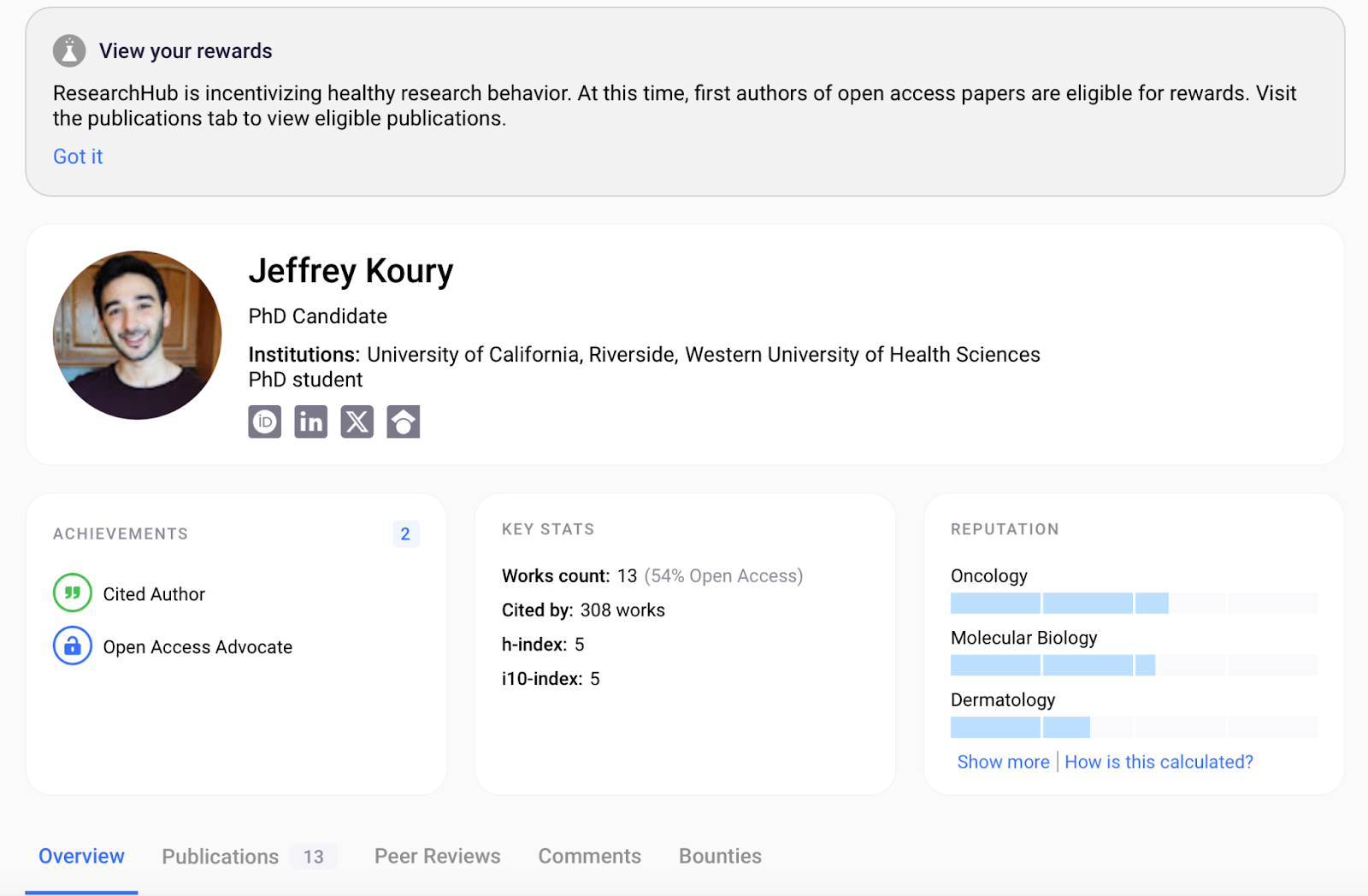
Subfields
Reputation is quantified across 248 research areas, termed “Subfields”. These Subfields are labeled using the OpenAlex topic classification system which leverages Scopus’ ASJC structure (see OpenAlex Topic Classification Whitepaper.docx). Through OpenAlex’s research information, we will be able to initialize Reputation and Author Profile Pages automatically for any researcher that verifies their identity, even one who has just joined ResearchHub for the first time.
An Iterative Approach to Reputation: "REP"
Reputation is quantified by assigning point values to various actions and outcomes - these points are termed REP. We are using citations to initialize Reputation in a way that allows us to continually iterate towards better, more comprehensive metrics. We’ve opted to begin with citations alongside upvotes as it is important to recognize the existing corpus of researchers. These researchers have contributed to their fields through publication and peer reviewed research in addition to ResearchHub specific actions (i.e. upvotes). We’ve built the framework for REP using a composable structure that allows us plenty of room to be creative and continually add more nuance.
Things we’re excited about considering in the future are: open access scores, reproducibility, cross-disciplinary work, innovation, and more. We’re excited to iterate on REP with the ResearchHub community over the next few years and continue to push towards our mission of accelerating the pace of scientific research.
Reputation Tiers
There are now 4 tiers of Reputation for every subfield on ResearchHub. These tiers are calculated by sampling all of the original research articles and preprints within that subfield and processing their citation counts. It is important to consider that the supply of citations in any given subfield varies considerably when comparing against the other subfields. For example, the average number of citations in the “Molecular Biology” subfield is X per article or preprint, while the average number in the “Machine Learning” subfield is just Y per article or preprint. This is because the culture, standards, and pace of research across subfields are not uniform and require nuance.
We’ve attempted to account for this nuance by ranking authors within each subfield based on their citation count. Tier 1 researchers who have already built Reputation through citations will be ranked in the 0-50th percentile of their subfield. Tier 2 researchers in the 50-70th percentile, Tier 3 in the 70-90th percentile, and Tier 4 in the 90-100th percentile. A value of REP is assigned per citation based on the supply of citations and log10 point values for tiers:
- Tier 1: 0 to 1,000 REP
- Tier 2: 1,001 to 10,000 REP
- Tier 3: 10,001 to 100,000 REP
- Tier 4: 100,001 to 1,000,000 REP
Earning Reputation
Reputation can be gained through actions on ResearchHub that result in upvotes or citations such as:
- Writing peer reviews
- Preregistering an experiment
- Completing research bounties
- Discussing scientific literature
- Publishing original research or review articles
Upvotes: Users will earn at least 1 REP per upvote received.
Citations Users will earn a variable amount of REP per citation, depending on their subfield and their Reputation Tier within that subfield. The amount of REP per citation is calculated as follows in any given subfield:

This results in a uniquely dynamic REP value per citation for each subfield, as a function of the supply of citations available in the field. To help illustrate this, you can find three examples below from the subfields of Molecular Biology (high supply of citations), Artificial Intelligence (medium supply of citations), and Philosophy (low supply of citations):
Example 1: Molecular Biology
The most cited researcher in Molecular Biology has 312,048 citations in original research articles or preprints.

Example 2: Artificial Intelligence subfield
The most cited researcher in Artificial Intelligence has 147,078 citations in original research articles or preprints.

Example 3: Philosophy subfield
The most cited researcher in Philosophy has 16,097 citations in original research articles or preprints.

These values of REP per citation are likely to change in the future as we continue iterating on the REP metric. We anticipate adjusting the balance of REP earned per upvote compared against citations in the medium term and will rely strongly on the feedback provided by the ResearchHub community.
Benefits of Reputation Tiers
Reputation tiers will eventually serve multiple purposes on the platform - as a starting point, REP tiers will provide:
- At-a-glance reputation - No need to wonder if you can trust a peer review, check for yourself if the researcher has a record of expertise in that subfield.
- Faster withdraws - All users will be able to withdraw at increased frequencies after they’ve verified their identity.
- Unverified Users: 2-week withdrawal cooldown
- Verified Users (Tiers 1 to 4): 24-hour withdrawal cooldown
Financial Incentives:
Beyond reputational incentives, we want to financially reward researchers who have participated in healthy research behaviors including:
- Publishing open-access articles/preprints
- Providing open-access data
- Preregistering studies
To this end, we have created author profiles for all researchers, and allowed 1st authors to claim RSC rewards for publications based on citation counts filtered through Open Access, Open Data, and Preregistration. The amount of RSC distributed per publication is dependent on the 1) subfield of the publication 2) number of citations and 3) the degree of “openness”, including open access, preregistration, and open data status.
*It is important to note that ResearchHub has implemented these financial incentives in a way that allows for and encourages continuous iterations/improvement. All of the structures described below are upgradable; please continue to provide us with feedback as we launch these new rewards.
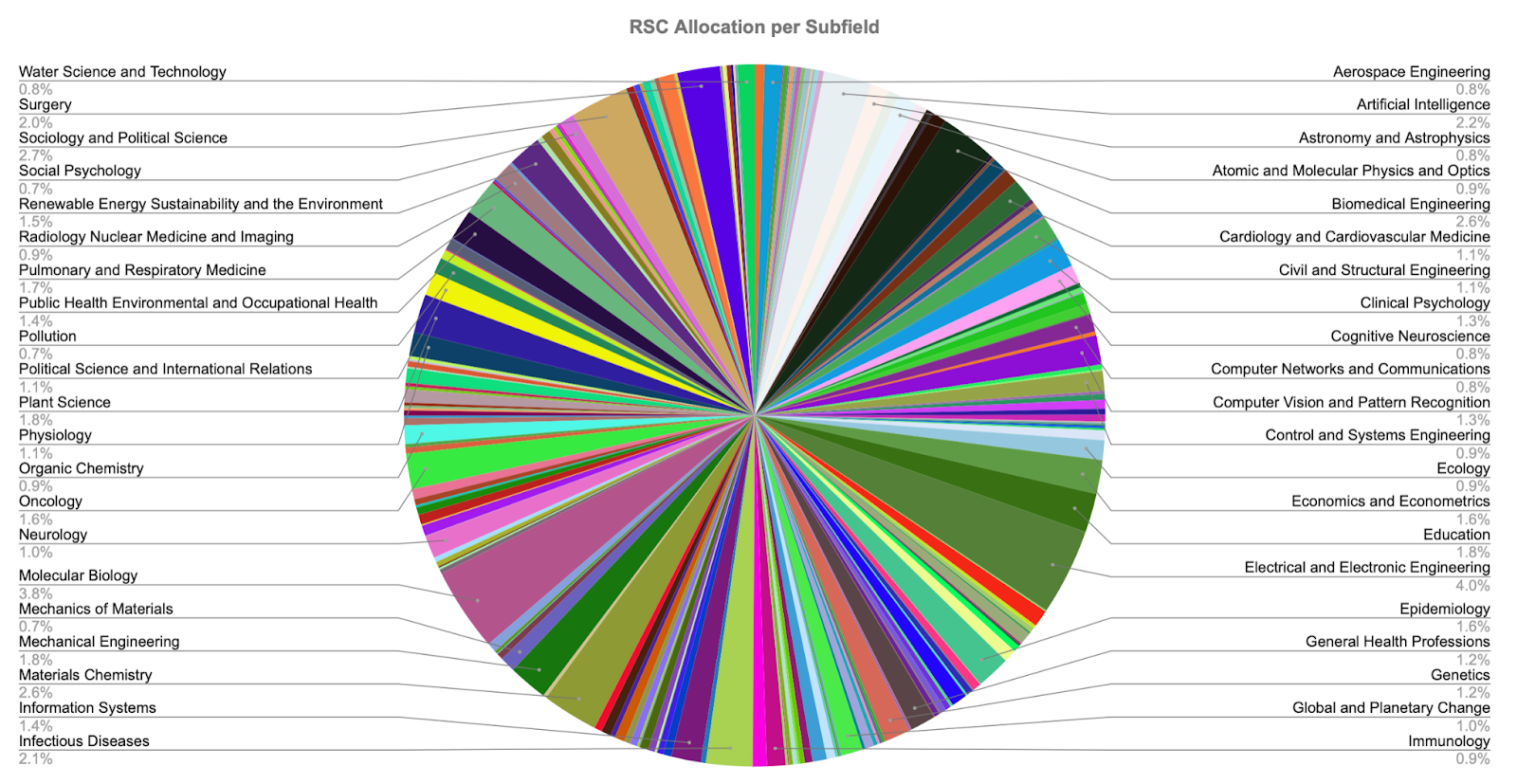
RSC Allocation per Subfield
Over the past 5 years of ResearchHub, the reward algorithm has under-emitted a total of 105M RSC. This RSC is set aside to be specifically used for incentivizing behavior that accelerates the pace of science - including actions that increase reproducibility. This provides a significant and unique opportunity to retrospectively reward researchers who have previously practiced healthy research behaviors.The challenge of establishing an initial condition for divvying up RSC across research disciplines is non-trivial. As a first pass, we’ve opted to distribute RSC as a function of the number of papers and number of citations in all subfields. We’ve used the date of the inception of ResearchHub (5 years ago - August 1st 2019), to the present day to represent this mission.
To this end, we calculated the total number of citations and total number of papers in each of the 248 subfields over the past 5 years. This provides us with a percentage value of the amount of citations and publications within a given subfield compared to the global research ecosystem. Given that both metrics alone would be insufficient for allocation, we opted to average these percentage weights to compute the RSC distributions. Final RSC distributions across all 248 subfields can be seen here: Healthy Rewards Per Subfield.xlsx as well as visually in the pie chart below.
RSC Per Paper (retrospective)
Choosing the ideal distribution of healthy research rewards within a subfield is also non-trivial and deserving of nuance. As an initial approach, we’ve chosen to use a Zipf’s law rank-based ordering system where publications within a given subfield are first ranked from 1 to N, where 1 is the most highly cited paper. You can find a step-by-step walkthrough of the calculations below.
1. Rank order all publications within each subfield by citation count
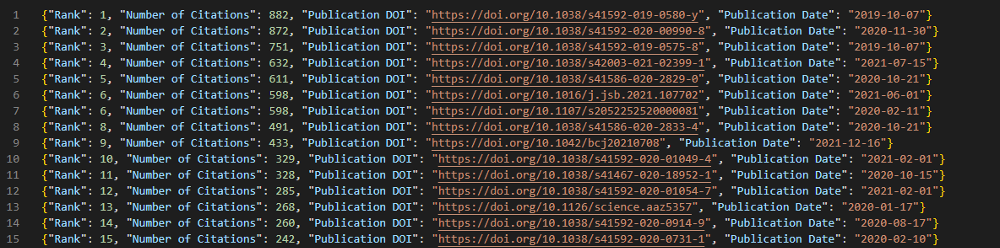
2. Fit a Zipf’s law model to each subfield
- Calculate a raw f(r) function value for each citation rank. We used an `s` value of 0.70 after qualitative inspection of RSC distributions.
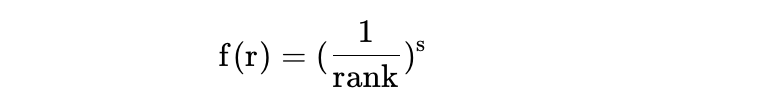
- Normalize all ranks by the summation of all f(r) values across citation ranks. This provides us with a rank-based weighting to distribute RSC within a subfield based on these fractional weights (f(r)).
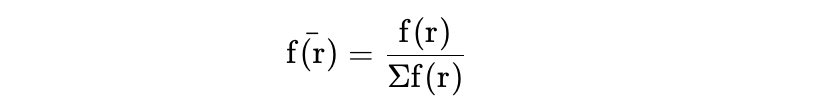
- RSC per citation was computed by multiplying these fractional weights (f(r)) by the RSC distributions per subfield (Healthy Rewards Per Subfield.xlsx).
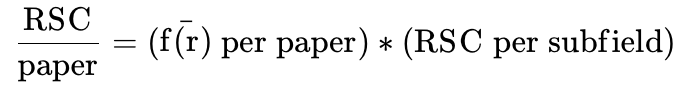
3. Approximate the Zipf’s law model for compatibility with the ResearchHub web app
- Generating a look-up table based on this rank-based system would be impractical for the ResearchHub web application. We were able to recover the Zipf’s law model in a more convenient manner by fitting a series of log-linear models to the RSC distributions, ordered by citations, which resulted in a qualitatively strong fit.
- We fit models for RSC distribution per citation in a series of 8 bins. These 8 bins allow us to utilize 8 log-linear models to approximate the more complicated underlying data in a manner that is easy to extend to future publications or non-perfectly fitting data (as exact citation counts are often in flux and vary by source). The log-linear models all follow the form shown below, where A and B are constants fit to each bin of the subfield models:
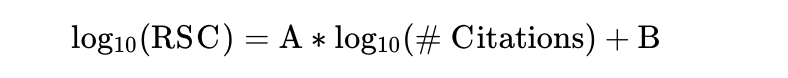
- All of the log-linear models and some RSC distribution metrics can be found in this Google Sheet: Healthy Rewards Piecewise Models
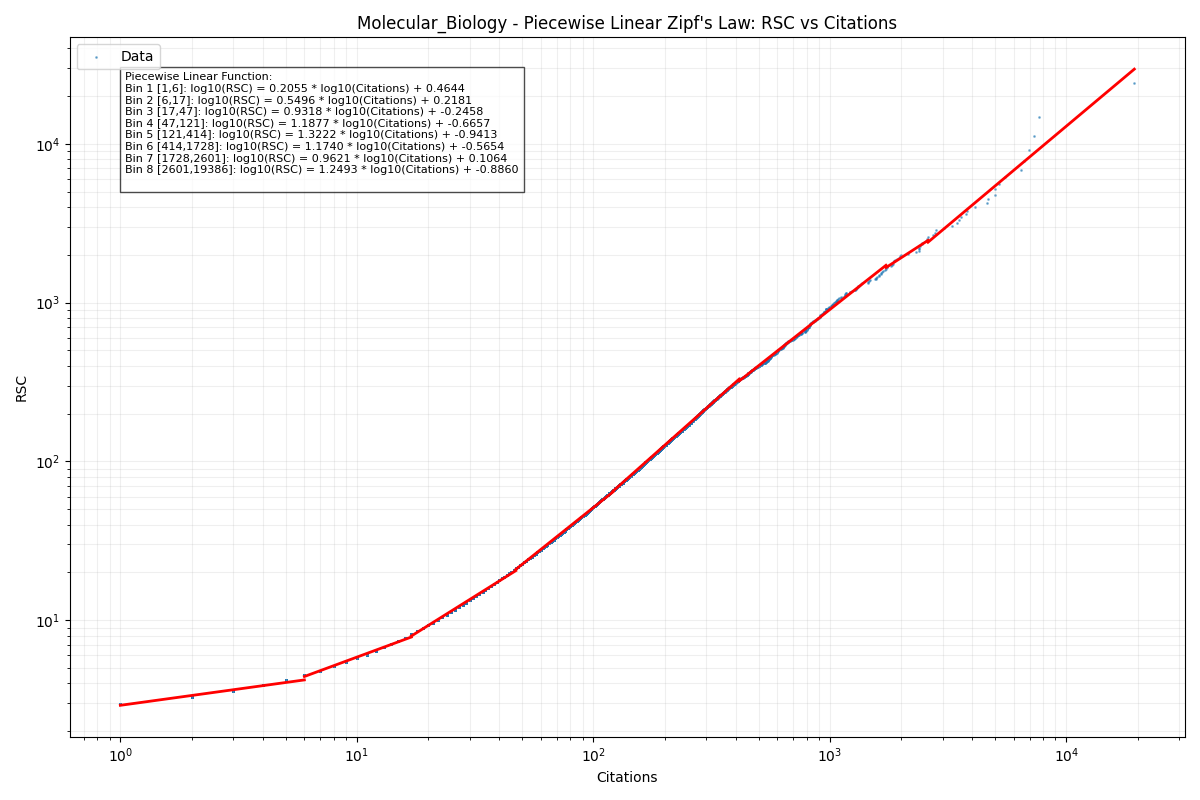
4. Scale the distributions by healthy research status
- The distributions shown in the Google Sheets and Plots are the upper limit of RSC that can be earned if the research is open Access, preregistered and has open data.
- Specifically, the following multipliers will be available for researchers:
- Open Access: 1x
- Preregistered: 2x
- Open Data: 3x
- Additionally, a flat multiplier of 5x will be applied to all rewards to account for the estimated fraction of articles/preprints that have reported open data and preregistrations.
- Open data is reportedly available in as little as 9-76% of cases, with 14-41% of open data requests to authors also being ignored [Tedersoo et al. 2021].
- Preregistrations are uncommon outside of the social sciences, where only 39% of authors had reported ever submitting a preregistration with their works [Sarafoglou et al. 2022].
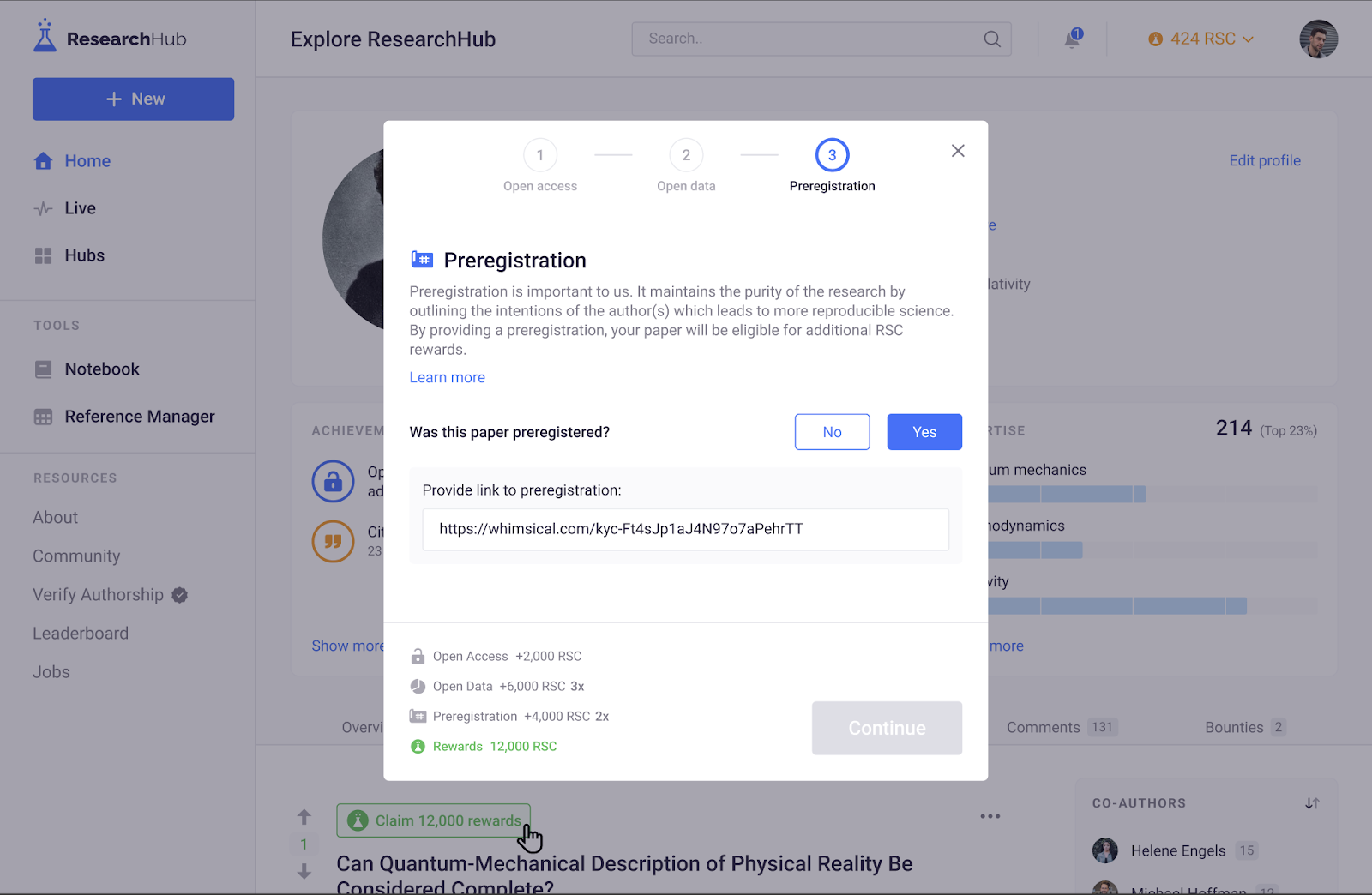
*The "multipliers" for open data and preregistration status are additive as shown above. For example, having open data and a preregistration attached to an open access article would result in 6x base rewards (open access: 2000 RSC base reward, open data: +3*2000 RSC (+6000 RSC), preregistration: +2x*2000 RSC (+4000 RSC, for a total of 12000 RSC)
Moving Forward
RSC per Citation (continuous)
As we’ve greatly enriched the data that underlies works on ResearchHub, we’re now able to provide rewards for more actions in scientific research. We will be adding the capability to distribute RSC rewards on citations moving forward in addition to upvotes. The exact details of this implementation are still being built but we’d love to hear your feedback about the best way to do this. Some open questions we have are:
- How should we reward citations on the various types of academic outputs (preprints, publications, conference papers, review papers)?
- Should upvotes distribute a flat 1 RSC per upvote?
- Should certain ResearchHub specific content/actions receive more distribution signal than others (e.g. peer reviews, preregistrations, original ResearchHub posts)?
Traditional Incentives vs. ResearchHub's Upgrade
Traditional academic incentives continue to undermine genuine scientific progress due to Goodharts’s law . The current system incentivizes questionable research practices driven by the pressure to publish, resulting in issues like p-hacking and selective reporting. ResearchHub addresses this by financially rewarding healthy research behaviors that prioritize transparency and reproducibility.
Traditional publishing is slow and burdened by extensive peer reviews, while ResearchHub offers instant publication for timely dissemination. Open access publishing often requires hefty fees that limit accessibility. At ResearchHub we reverse this by paying researchers to make their work freely available, which we hope will incentivize openness.
Where competition dominates traditional academia, ResearchHub promotes collaboration by rewarding shared insights and collective progress. Reputation in the current system is controlled by gatekeepers and metrics like impact factors. This novel bottom-up reputation system is driven democratically by community consensus.
Finally, instead of ineffective metrics like h-index, ResearchHub provides modular reputation and expert identification at a glance. This improvement offers nuanced recognition across specific fields. In short, we’re not just patching up the flaws in academia—we’re creating a fundamentally new ecosystem that realigns incentives with the core values of science: transparency, collaboration, and integrity.

Closing Thoughts
We are eager to release these new incentive structures on the ResearchHub platform and are looking forward to hearing critical feedback from our community. It is important that we make sure these rewards are incentivizing healthy research behavior. In the words of the great American biochemist, Linus Pauling:
"If you want to have good ideas you must have many ideas. Most of them will be wrong, and what you have to learn is which ones to throw away."
- Linus Pauling
We will continue to iterate on these models for the foreseeable future in hopes of stepping closer towards a better future for scientific research.
Thank You Message
Thank you to the following people who read the draft of this post, helped make this new feature a reality, and contributed in every small way possible, including: Brian Armstrong, Kobe Attias, Gregor Zurowski, Taki Koutsomiti, Jeffrey Koury, Riccardo Goldoni, and Arshia Malek.
Tell us what you think
If you’d like to chat with members of the ResearchHub and ResearchHub Foundation team, consider connecting with us in the ResearchHub Discord or reach out to us via X/Twitter, LinkedIn, or email.
ResearchHub
- Discord: https://discord.com/invite/ZcCYgcnUp5
- X/Twitter: https://x.com/researchhub
- LinkedIn: https://www.linkedin.com/company/researchhubtechnologies/
ResearchHub Foundation
- X/Twitter: https://x.com/researchhubf
- LinkedIn: https://www.linkedin.com/company/researchhub-foundation



